


出品 | 搜狐科技
作者 | 梁昌均
编辑 | 杨锦
开卷推理大模型!OpenAI的秘密要被揭开了?
1月20日晚,月之暗面(Kimi)、深度求索(DeepSeek)撞车发布最新深度推理模型,均称性能对标OpenAI “满血版”o1,并公开技术报告。
Kimi这次发布的是k1.5多模态思考模型。该公司称,从基准测试看,该模型实现了SOTA(最先进)级别的多模态推理和通用推理能力。
“这应该是全球范围内,OpenAI之外的公司首次实现o1正式版的多模态推理性能。”Kimi说。
大模型黑马DeepSeek可能“不服”。该公司发布的开源推理模型DeepSeek-R1,性能亦比肩OpenAI o1正式版,加之极低的价格,再次引发热议。
“这不可能是巧合。”英伟达高级研究科学家Jim Fan先后转发这两款模型信息,并再对DeepSeek发出称赞:“他们或许是第一个展示强化学习飞轮效应,且持续增长的开源项目……这真是一个天才的团队。”
从最领先的模型能力看,到底谁才是中国的OpenAI,这一刻似乎不再仅有一个答案。至少现在,Kimi、DeepSeek已是最有实力的竞争者。
同时,追赶者甚众。早前,科大讯飞、商汤、智谱、MiniMax、阶跃星辰等多家AI企业都先后推出强调推理性能的模型,谷歌也在紧追OpenAI。新一轮的大模型技术竞赛又开始了!
Kimi撞车DeepSeek,媲美o1的国产推理王者来了
Kimi此次发布的k1.5多模态思考模型,是其最近三个月以来在推理模型上的持续升级。
据技术报告,在 short-CoT(短思维链)模式下,k1.5的数学、代码、视觉多模态和通用能力,超过GPT-4o和Claude 3.5 Sonnet等模型。同时,多个基准测试超过通义、DeepSeek、Llama等国内外领先开源模型。
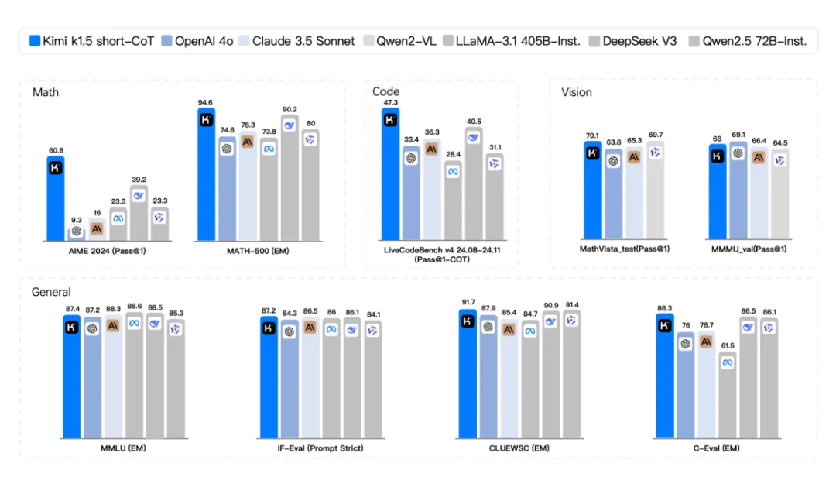
在long-CoT(长思维链)模式下,k1.5的数学、代码、多模态推理能力,基本达到OpenAI o1正式版的水平,仅有编码和视觉能力的部分测试(如更为全面且动态的编码测试基准LiveCodeBench v5)不及o1水平。
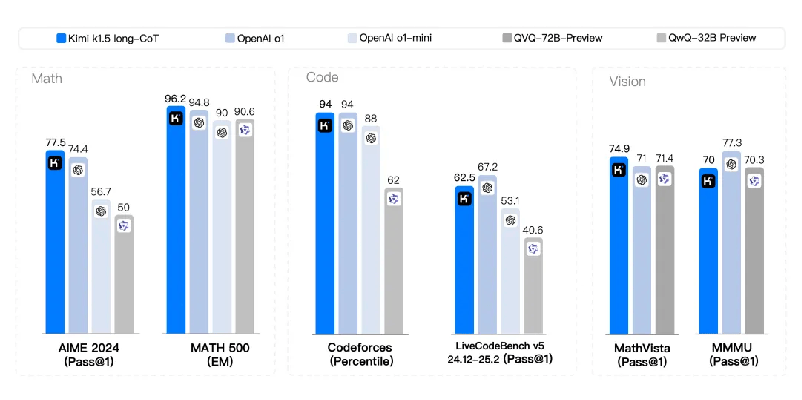
DeepSeek同一天发布模型参数660B的DeepSeek-R1,号称在数学、代码、自然语言推理等任务上,性能也比肩OpenAI o1正式版,仅有部分测试相较o1稍有逊色。
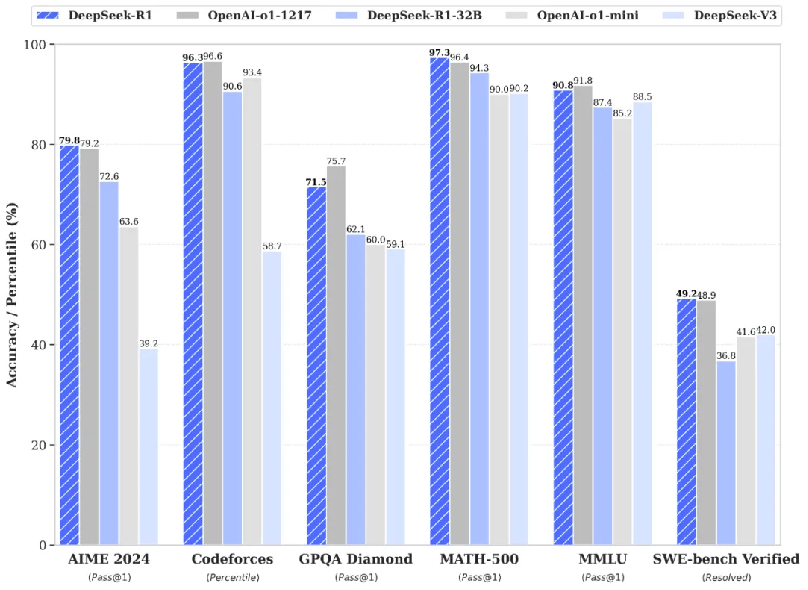
这两个在同一天发布,且均号称对标o1的国产模型,谁更强?搜狐科技对比发现,在数学能力方面,Kimi k1.5在AIME2024和MATH500两个主流基准测试中均不及DeepSeek-R1。
同时,在代码基准Codeforces,以及多任务语言理解MMLU测试中,k1.5亦不及DeepSeek-R1。但与k1.5对比,DeepSeek-R1尚不具备视觉等多模态能力。
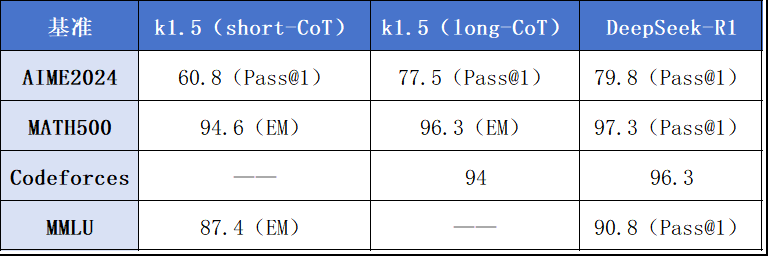
k1.5和DeepSeek-R1相同基准表现(EM为多次生成的准确性,Pass@1为单次生成的准确性)
更让不少开发者兴奋的是,DeepSeek-R1依然开源,并通过DeepSeek-R1蒸馏了6个小模型进行开源,其中32B和70B模型在多项能力对标OpenAI o1-mini的效果。
DeepSeek还宣布,模型将完全开源、不限制商用,允许用户利用模型输出、通过蒸馏等方式训练其他模型,并对用户开放思维链输出。
同时,DeepSeek沿袭了“大模型界拼多多”的风格。DeepSeek-R1的API定价为每百万输入 tokens 1元(缓存命中/4元(缓存未命中),每百万输出tokens 16元,不到o1的4%。
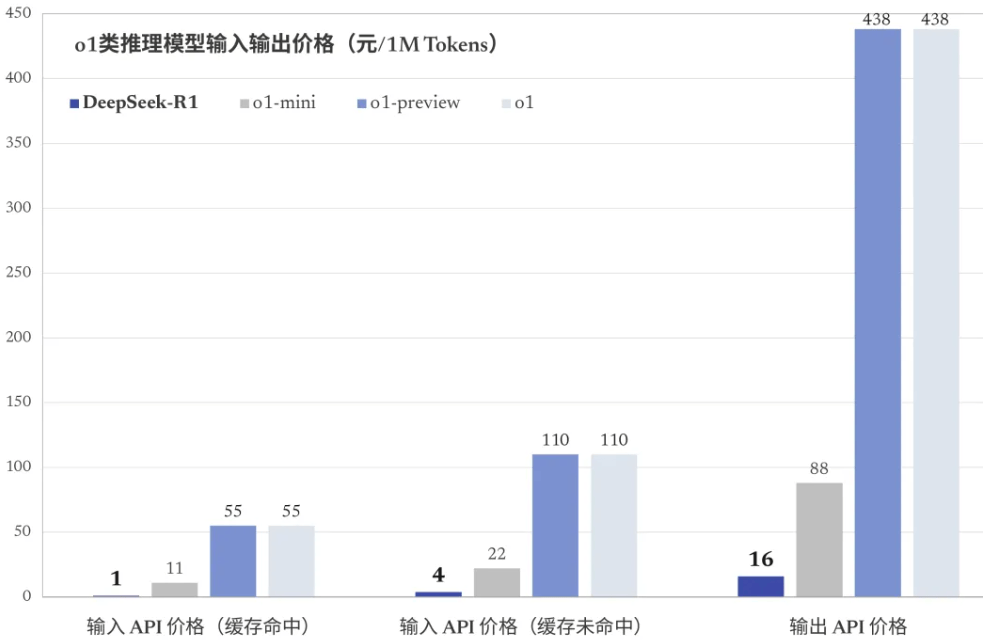
中国同时发布两个类o1 模型,并实现对OpenAI的对标,引发热议,尤其是开源的DeepSeek-R1再次受到不少认可,目前其在开源社区GitHub获得近万颗星。
“这才是真正的OpenAI!”有网友称,DeepSeek才是真正继承了OpenAI最初使命的团队。
英伟达高级研究科学家Jim Fan这次又对其称赞到:“一家非美国公司正在让OpenAl的最初使命继续存在——做真正开放、前沿的研究,并为所有人赋能。”
去年12月底,DeepSeek开源6710亿参数的DeepSeek-V3,起以不到600万美元的训练成本,媲美全球最强模型,让这家低调的公司进一步出圈。
硅基流动创始人&CEO袁进辉读完DeepSeek-R1的技术论文,感觉又一次被震惊。“从V3到 R1,DeepSeek完成了对OpenAI的从致敬到超越,这让我有点相信梁文锋说的ASI了。”
作为DeepSeek的创始人,梁文锋坚信ASI会到来。最近,他还参加了政府最高规格座谈会。
强化学习再立功,走出大模型性能提升新路径
和o1一样,Kimi和DeepSeek这次在模型推理性能的提升,得益于强化学习的力量。
k1.5和DeepSeek-R1的技术论文题目,均强调了强化学习(RL,Reinforcement Learning)的作用,这两款模型均是利用强化学习进行训练。

强化学习并不是特别新的算法,其由“强化学习之父”理查德·萨顿(Richard Sutton)在2010年左右提出,属于机器学习的分支之一。
早在2016年,谷歌旗下的围棋机器人AlphaGo先后打败李世石和柯洁等世界围棋冠军,背后借助的正是强化学习的能力。
虽然Kimi和DeepSeek的这两款模型都利用了强化学习进行模型训练,且没有采用AlphaGo使用的蒙特卡罗树搜索(MCTS)、过程奖励模型(PRM)等算法,但具体实现路径有所差异。
Jim Fan提到,DeepSeek的模型完全由强化学习驱动,没有任何监督微调(SFT),即“冷启动”。“这让人想起AlphaZero——从零开始掌握围棋、将棋和国际象棋,而不是先模仿人类大师的棋局,这是论文中最重要的收获。”
与此不同的是,Kimi采用的是类似AlphaGo Master方法,通过提示工程构建的思维链轨迹进行轻量级监督微调以进行预训练。
AlphaZero和AlphaGo Master是谷歌当年推出的不同版本的下棋机器人,前者无需人类棋谱数据,完全依赖自我对弈进行训练;后者则是AlphaGo的升级版,使用人类棋谱数据进行训练,从而模仿学习人类的下棋策略。
一般来说,大模型包括预训练、监督微调、奖励建模、强化学习四个训练阶段,这基本由OpenAI定义。现在,月之暗面和DeepSeek则探索出“可能”的新路径。
k1.5通过预训练、监督微调、长思维链(CoT)监督微调和强化学习,实现推理性能的提升。DeepSeek-R1更为“大胆”,拒绝采样和监督微调,仅靠强化学习进行训练,而以往则要依赖大量监督数据来提升模型性能。
“这标志着研究社区的一个重要里程碑。这也是第一个公开的研究,证明大语言模型的推理能力可以完全通过强化学习激励,而不必使用SFT来验证。”DeepSeek在论文中提到。
值得关注的是,DeepSeek在论文中还提到了模型的“aha时刻”(顿悟时刻)——DeepSeek-R1-Zero学会拟人化的语气重新思考。“这显示了强化学习在解锁AI智能方面的潜力,为未来更自主、适应性更强的模型铺平道路。”

AI计算资源公司Hyperbolic Labs 创始人&CTO金宇辰认为,这个“顿悟时刻”意义重大:纯强化学习能够让大语言模型学会思考和反思。“这挑战了此前的信念,即复制o1推理模型需要大量的思维链数据。事实证明,只需要给它正确的激励就行。”
K1.5的训练过程也有类似发现。月之暗面研究员Flood Sung公开发文称,团队在实际训练过程中发现,模型会随着训练提升性能,并不断增加token数。
“这是强化学习训练过程中模型自己涌现的!这和友商Deepseek的发现几乎一样。他们直接做了无监督微调的强化学习,也是挺impressive!”
袁进辉对此也表示,如果说DeepSeek-V3的思路还都在想象范围内,更多是惊艳的工程交付能力,DeepSeek-R1就是纯粹的无人区探索和发现。“可能OpenAI已经这么做了,但没公开,也可能DeepSeek-R1的做法比OpenAI还要好。”
众所周知,o1是通过强化学习和思维链进行训练,但OpenAI并未披露训练过程。现在,o1的秘密已被揭晓。有评论称,这意味着硅谷AI霸权和神话破灭的开始。
开卷推理模型,新的大模型技术竞赛开始了
业内对推理模型的关注始于去年9月,当时OpenAI发布首款具备深度推理能力的o1预览版,12月发布正式版,并预告将推出更为强大的o3模型。
这也推动大模型,从预训练Scaling Law转向后训练Scaling Law。通过强化学习等提高模型推理能力,成为国内外AI企业追求的主流方向之一。
Flood Sung分享到,o1发布后效果爆炸,而Kimi团队一年多前就验证过长思维链的有效性。但当时团队意识到长文本的重要性,率先考虑把文本搞长,而对长思维链不够重视。
“成本速度有摩尔定律加持,可以不断下降,只要把性能搞上去,剩下的都不是主要问题。所以我们得搞Long CoT,搞o1。”Flood Sung正是这次k1.5的研发人员之一。
在去年11月的媒体沟通中,Kimi创始人杨植麟强调,接下来AI发展的方向,要通过强化学习去扩展。当时,Kimi发布了首个主打推理能力的k0-math模型,12月又发布k1视觉模型。按月之暗面的话来说,这些工作并未产生具有竞争力的结果,但k1.5做到了。
实际上,除了Kimi和DeepSeek,最近国内不少企业都在密集发布内部的首个推理模型,包括科大讯飞、商汤、智谱、MiniMax、阶跃星辰等多家AI企业。
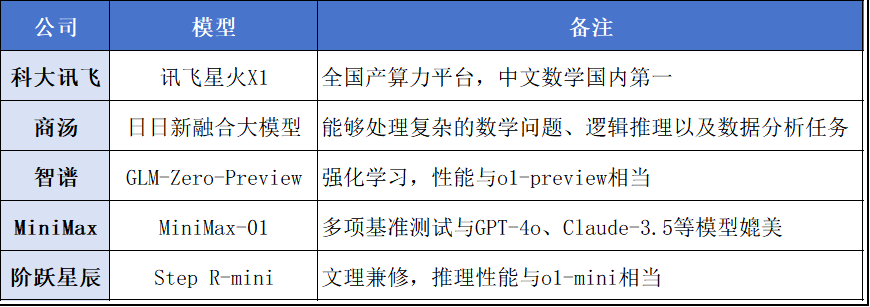
这些模型各有各的特色,如讯飞星火X1是首个基于全国产算力平台进行训练的推理模型,商汤的日日新融合大模型具备多模态能力,阶跃星辰的Step R-mini则强调文理兼修。
不过,这些模型在推理性能方面普遍不及o1正式版。Kimi和DeepSeek显然已是领头羊,并为业内提供了值得借鉴的探索路径,即利用强化学习的力量。
萨顿此前就批评到,目前的AI,包括大模型,过度依赖深度学习。“某种意义上,我相信强化学习是AI的未来。”
AI大神安德烈·卡帕蒂(Andrej Karpathy)此前表示,更看好AlphaGo那样的自博弈的强化学习,认为没有人工干预的自我进化才是大模型的未来。
就在昨日,谷歌还发布了Gemini2.0Flash Thinking 推理模型的增强版,和OpenAI争锋相对。最近,o3陷入数学成绩作弊质疑,OpenAI通过赞助拿到了严格保密的题目。
谷歌AI负责人Jeff Dean表示,该模型不仅延续了原有版本的优点,还新增了基于思维增强推理能力的功能,表现出色,夺回 Chatbot Arena榜首,并将继续探索。
“这是一场通往多模态推理未来的竞赛,这些涌现出来的新模型,正在使AI竞赛升温。”有外国网友甚至还提到,“中国将引领AGI之路”。
Kimi表示,2025年继续沿着路线图,加速升级k系列强化学习模型,带来更多模态、更多领域的能力和更强的通用能力。

DeepSeek则表示,未来将围绕更多通用能力、混合语言、提示工程、软件工程任务等方面继续提升DeepSeek-R1的表现。
智谱也坦言,GLM-Zero-Preview与o3还有不少差距。未来将持续优化迭代强化学习技术,并将很快推出正式版GLM-Zero,将深度思考的能力从数理逻辑扩展到更多更通用的技术。
“我们正在进入大语言模型的强化学习时代,2025年可能是强化学习的年份。”金宇辰表示。
现在,这场新的大模型技术竞赛,风起于太平洋两岸,而中国的AI企业已探索出属于自己的路。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






